使用Uniscribe 处理复杂文本(一)
站长推荐:NSetup一键部署软件
一键式完成美化安装包制作,自动增量升级,数据统计,数字签名。应对各种复杂场景,脚本模块化拆分,常规复杂的脚本代码,图形化设置。无需专业的研发经验,轻松完成项目部署。(www.nsetup.cn)
Uniscribe
Uniscribe 简介
Uniscribe 是微软推出的一个用于解决复杂文本处理的API 集合。它在Windows 中与GDI 函数集合之间的关系如下图所示:
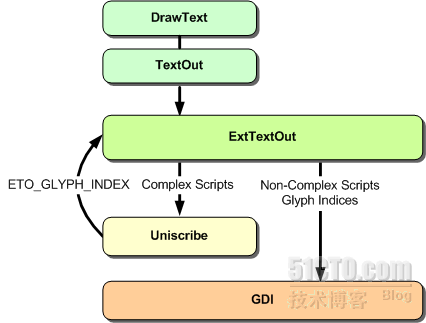
当我们需要输出一段文本时,调用文本输出函数ExtTextOut,Windows 内部会进行一次判断过程,如果当前文本是复杂文本,它会先调用Uniscribe 函数集对文本进行一次预处理,随后将处理的结果返回给ExtTextOut 函数,这个结果是字形的索引值。
让我们先来看一看具体的工作流程是怎样的,伪代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
[cce_cpp] void ExtTextOut( int iX, int iY, const TCHAR* strText, int iTextLength ) // 此处标志位一般为ETO_CLIPPED 等 { if ( ScriptIsComplex( strText ) ) { // 进行复杂文本处理 // 调用Uniscribe 引擎 ScriptItemize(); ScriptShape(); ScriptPlace(); // 通过上面三步骤得到 字形集合、字形宽度、字形偏移 // 调用ScriptTextOut 进行输出 ScriptTextOut() { // TextOut 函数内部 // 首先根据字形偏移将字形集合分为偏移相同的几个部分 // 对每个部分调用ExtTextOut (标志位设置 ETO_GLYPH_INDEX)进行输出,当然要计算坐标值, // 坐标值根据字形宽度和字形偏移进行计算 } } else { // 简单文本 // 直接将字符转换为字形 int* pGlphy = new int[iTextLength]; FormatCharToGlphy( strText, iTextLength, pGlphy ); // 计算每个字形的宽度 int* pGlphyWidth = new int[iTextLength]; // 循环输出字形 for ( int i = 0; i < iTextLength; ++i ) { GlphyOut( iX, iY, pGlphy[0] ); iX += pGlphyWidth[i]; } } } [/cce_cpp] |
上面的代码中提到了“字形”这个概念,所谓字形是指一个字符在一种字体环境下显示的形状,字形值是标识字符在某种字体下的位置,我门通过字符A的编码值和字体名称(如“宋体”)能够找到一个对应的字形(字形值是36),当然前提条件是这种字体支持字符。在这里要强调一下,并不是一个字符对应一个字形,可能几个字符对应一个字形,也可能几个字形对应一个字符,同时在一种字体环境下,一个字符在不同的上下文中对应的字形也可能不同(阿拉伯)。
我们在日常的程序开发中并不需要掌握Uniscribe 函数集的使用,因为GDI 和GDI+ 函数已经很好的帮我们封装了Uniscribe 的实现细节了。除非我们需要开发一个类似“记事本”或者“Word” 一样的具有良好全球化性质的软件,因此本文的主要目的是针对那些需要开发“复杂文本处理软件”的朋友们。
Uniscribe 的主要目的是对复杂文本进行处理,何为复杂文本?一般而言复杂文本是指那些处理起来比较复杂的文本。这不是废话吗!复杂文本一般在以下5 个方面(详见MSDN About Uniscribe):
1.渲染方向,这个世界有一些国家的文字绘制方向是从有到左的,如阿拉伯、希伯来文等,
2.语境具体化,有些字符在不同的上下文下显示的字形不一样,如阿拉伯文
3.组合字符,组合字符,有些字符能够附加在其他字符之上,我们称之为寄生字符,而被寄生的字符称为宿主字符,它们的结合体称为组合字符,比如泰文บึ,阿拉伯文ىْ,不过有些寄生字符在一定上下文环境下不允许被显示。此外还有一种组合字符,它是编码长度为4 的字符(本文编码方式为UTF16),又称大字符。因为它占有两个普通字符的空间,因此也可以看成组合字符。为方便记忆,前者称为真组合字符(确实有多个字符),后者称为假组合字符,所有的真组合字符宿主字符的逻辑位置(字符索引)均在寄生字符前侧
4.自动换行,使用过记事本的人都知道,当一个单词无法在一行显示完全时,会自动换到下一行显示,我们不希望一个单词的前一部分显示在一行结尾,而后一部分显示在下一行的开头
5.字体回退,如果所有的字体都能够完美的支持地球上所有国家的文字,那就不需要所谓的字体回退了。正因为每种字体都是有缺陷的,所以在一种字体环境下显示一段多国语言文本时可能会出现有些字符在当前字体找不到对应的字形而无法显示,这样会给用户带来极差的体验
所以我们需要对复杂文本进行特殊处理,我们需要Uniscribe 或者类似的文本处理引擎。
学习日记,兼职软件设计,软件修改,毕业设计。
本文出自 学习日记,转载时请注明出处及相应链接。
本文永久链接: https://www.softwareace.cn/?p=299